
Table of Links
2. Preliminaries and 2.1. Blind deconvolution
2.2. Quadratic neural networks
3.1. Time domain quadratic convolutional filter
3.2. Superiority of cyclic features extraction by QCNN
3.3. Frequency domain linear filter with envelope spectrum objective function
3.4. Integral optimization with uncertainty-aware weighing scheme
4. Computational experiments
4.1. Experimental configurations
4.3. Case study 2: JNU dataset
4.4. Case study 3: HIT dataset
5. Computational experiments
5.2. Classification results on various noise conditions
5.3. Employing ClassBD to deep learning classifiers
5.4. Employing ClassBD to machine learning classifiers
5.5. Feature extraction ability of quadratic and conventional networks
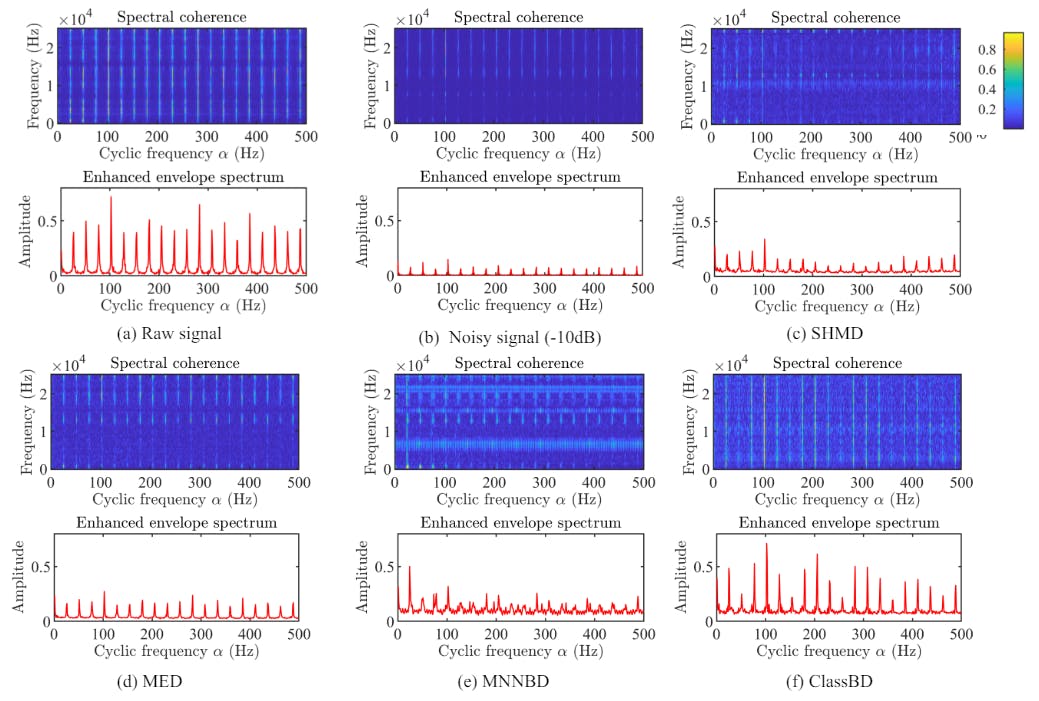
5.6. Comparison of ClassBD filters
5.3. Employing ClassBD to deep learning classifiers
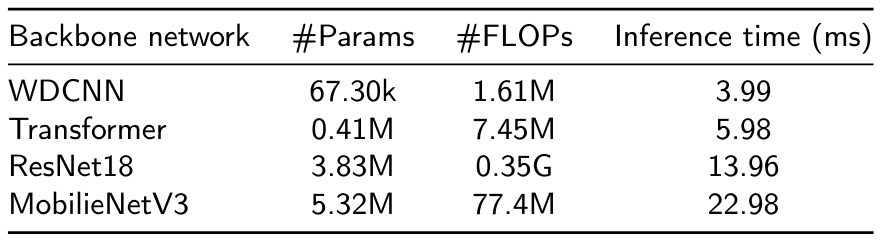
Given that ClassBD serves as a signal preprocessing module, it possesses the flexibility to be integrated into various backbone networks. In the context of this experiment, we assess the classification performance by incorporating ClassBD into four widely recognized deep learning classifiers: ResNet [85], MobileNetV3 [86], WDCNN [54], and Transformer [87]. It is important to note that some networks were initially designed for image classification, so some parameters are revised to accommodate the 1D signal input. The properties of these backbone networks are illustrated in Table 11.
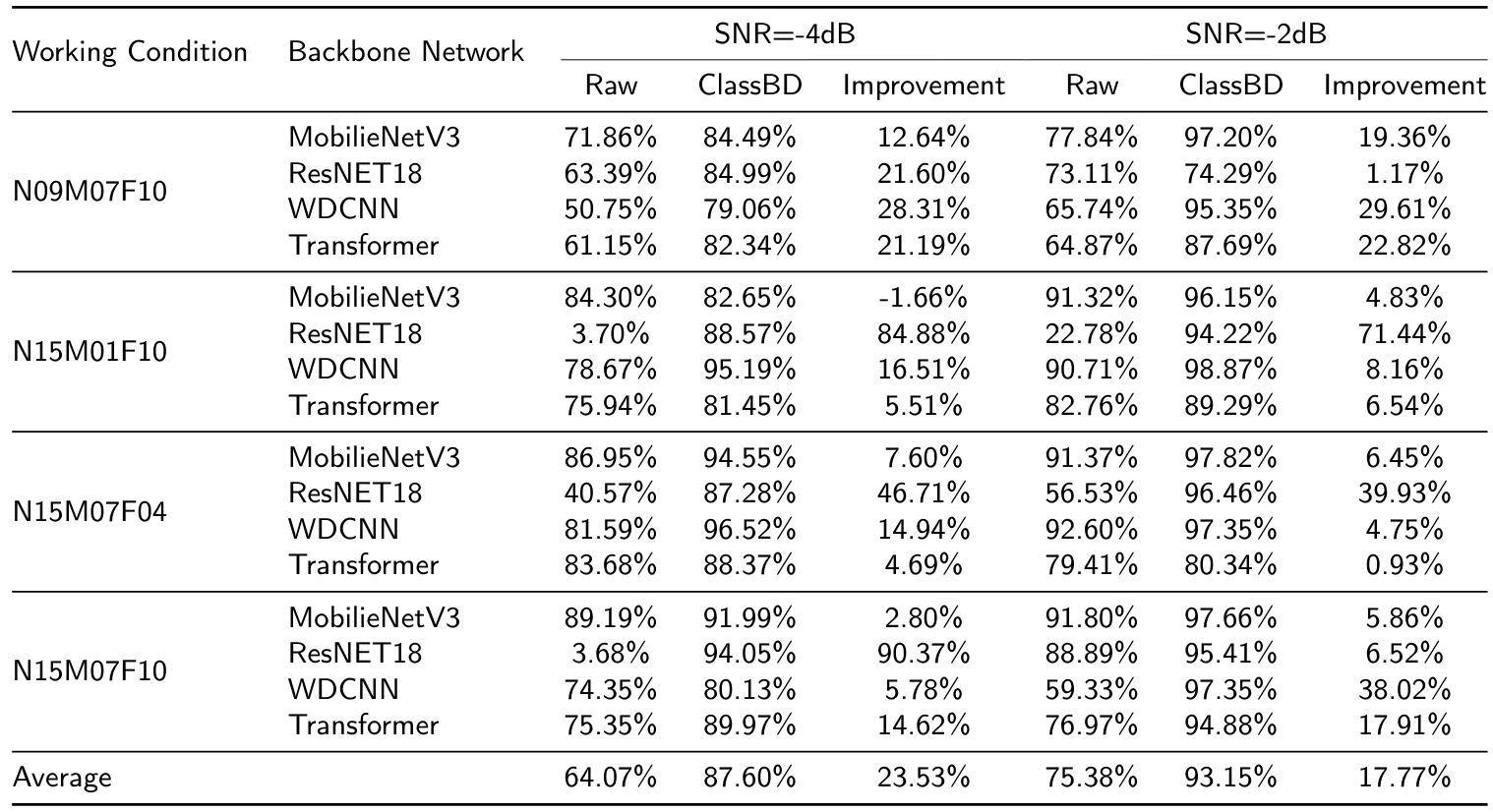
Firstly, the classification results on the PU dataset are illustrated in Table 12. Predominantly, ClassBD has demonstrated its efficacy in enhancing performance. For instance, in the case of N09M07F10 with -4dB noise, the application of ClassBD results in an improvement exceeding 10% across all backbones. On average, when the SNR is -4dB, ClassBD achieves F1 scores of 87.60%, whereas the raw networks only yield 64.07%.
Subsequently, we also test these models to the JNU and HIT datasets, setting the SNRs to -6dB and -4dB respectively. As depicted in Table 13, ClassBD exhibits commendable performance on both datasets, and all backbones experience a performance boost. Specifically, on the JNU dataset, the F1 scores exceed 90% post the employment of ClassBD, irrespective of the backbone performance. Furthermore, a substantial improvement is observed in the Transformer. The raw Transformer initially yields F1 scores around 50% on the JNU and HIT datasets, which, after the application of ClassBD, escalates to an average F1 score of 90%.
Finally, the results on the three datasets suggest that ClassBD can function as a plug-and-play denoising module, thereby enhancing the performance of deep learning classifiers under substantial noise. Considering both performance and model size, the simplest backbone, WDCNN, achieves consistent performance under all conditions. Consequently, we recommend it as the backbone for bearing fault diagnosis.
Authors:
(1) Jing-Xiao Liao, Department of Industrial and Systems Engineering, The Hong Kong Polytechnic University, Hong Kong, Special Administrative Region of China and School of Instrumentation Science and Engineering, Harbin Institute of Technology, Harbin, China;
(2) Chao He, School of Mechanical, Electronic and Control Engineering, Beijing Jiaotong University, Beijing, China;
(3) Jipu Li, Department of Industrial and Systems Engineering, The Hong Kong Polytechnic University, Hong Kong, Special Administrative Region of China;
(4) Jinwei Sun, School of Instrumentation Science and Engineering, Harbin Institute of Technology, Harbin, China;
(5) Shiping Zhang (Corresponding author), School of Instrumentation Science and Engineering, Harbin Institute of Technology, Harbin, China;
(6) Xiaoge Zhang (Corresponding author), Department of Industrial and Systems Engineering, The Hong Kong Polytechnic University, Hong Kong, Special Administrative Region of China.
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.